伙伴系统
rCore 采用经典的伙伴系统(Buddy System)做堆内存分配。源码地址:
该算法会将空闲内存按 2 的幂次划分,在分配时按需拆分,在释放时逐级合并,从而满足不同大小的申请需求。下面结合示例代码和调试截图,逐步讲解大致流程。
侵入式链表
伙伴系统依赖侵入式链表来管理各个阶次的空闲内存块,每个阶次维护一个链表存储相同大小的可用块。为了便于调试和理解实现细节,将侵入式链表的相关代码放置在
ch1 分支中。由于此分支 rCore 的结构较为简单,每次运行时变量的内存地址基本保持一致,便于观察和分析。
其中,linked_list.rs 文件从伙伴系统项目复制并为方便调试进行了改动:
同时,test.rs 文件同样为方便调试进行了修改:
构建节点的值
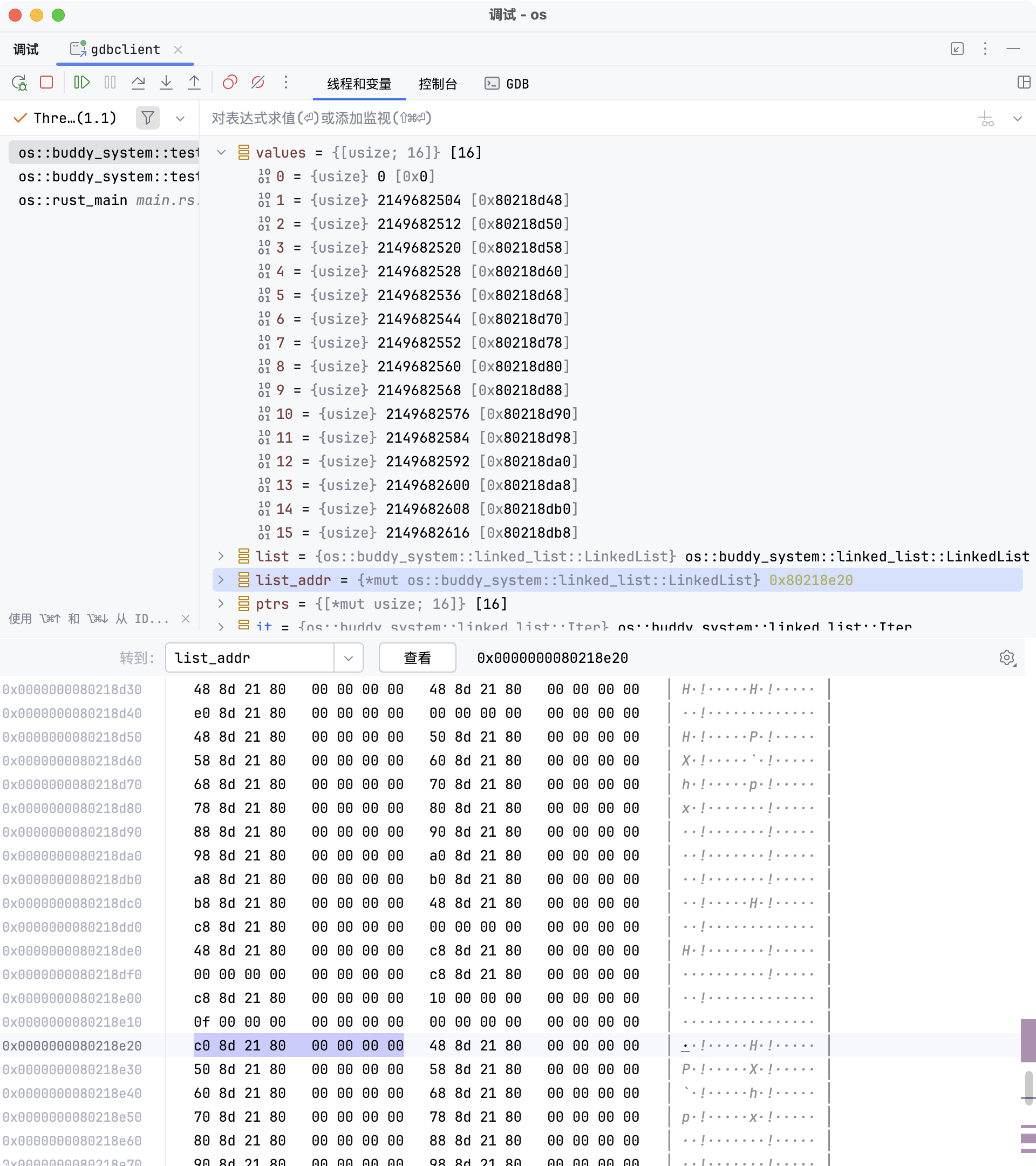
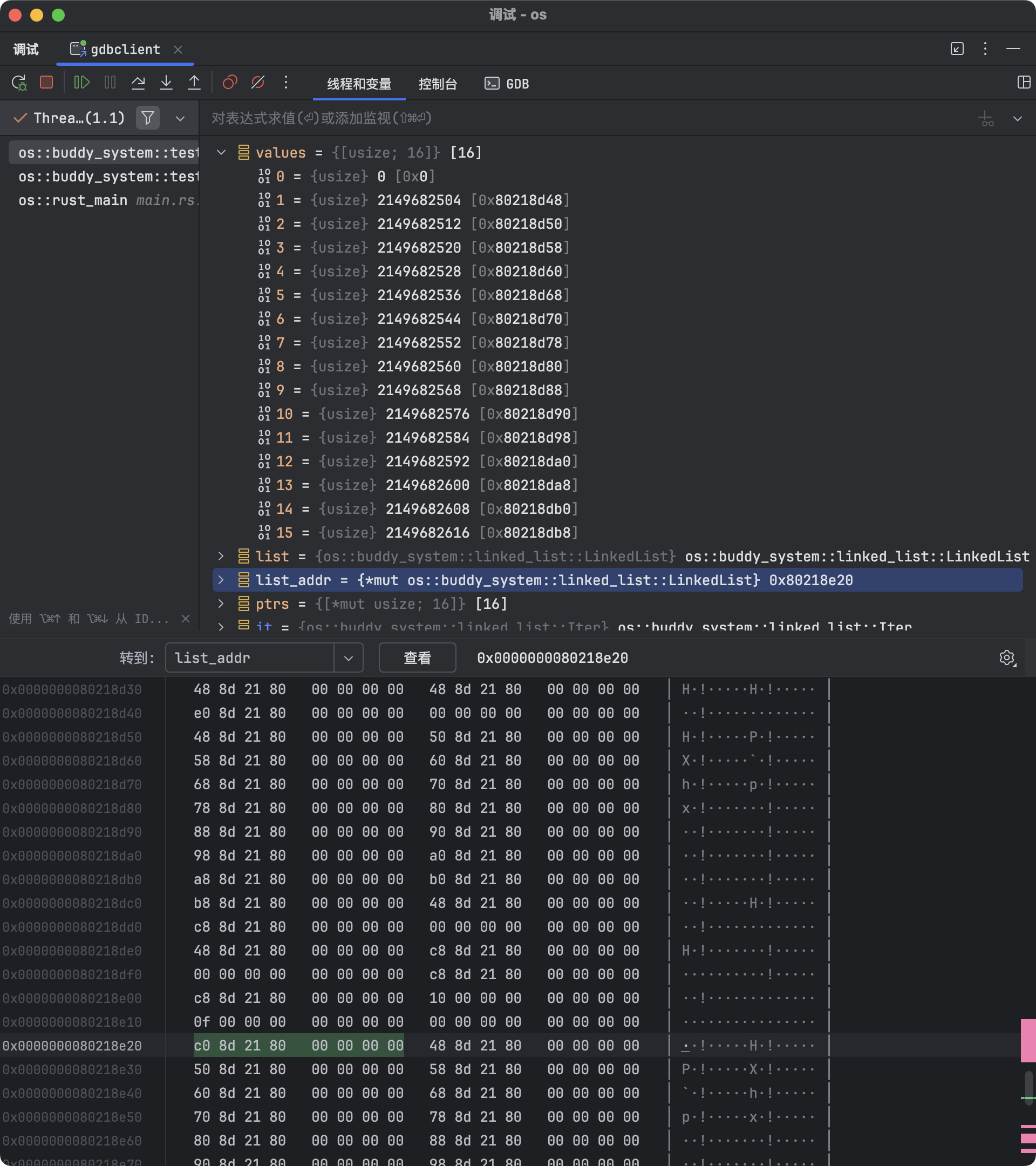
下图展示的是【2. 新建 list 并保存它的地址以便调试】之前的断点状态:
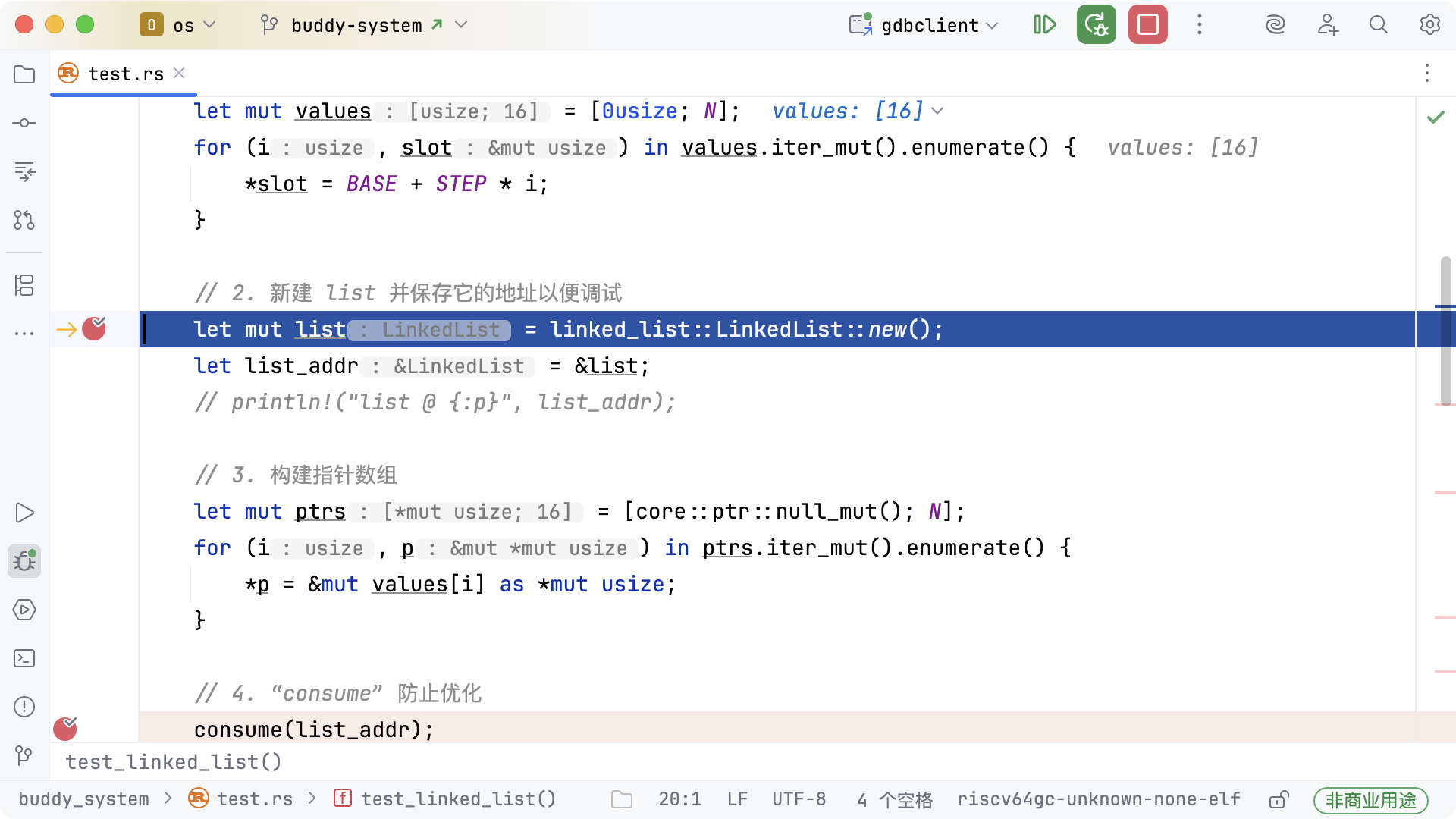
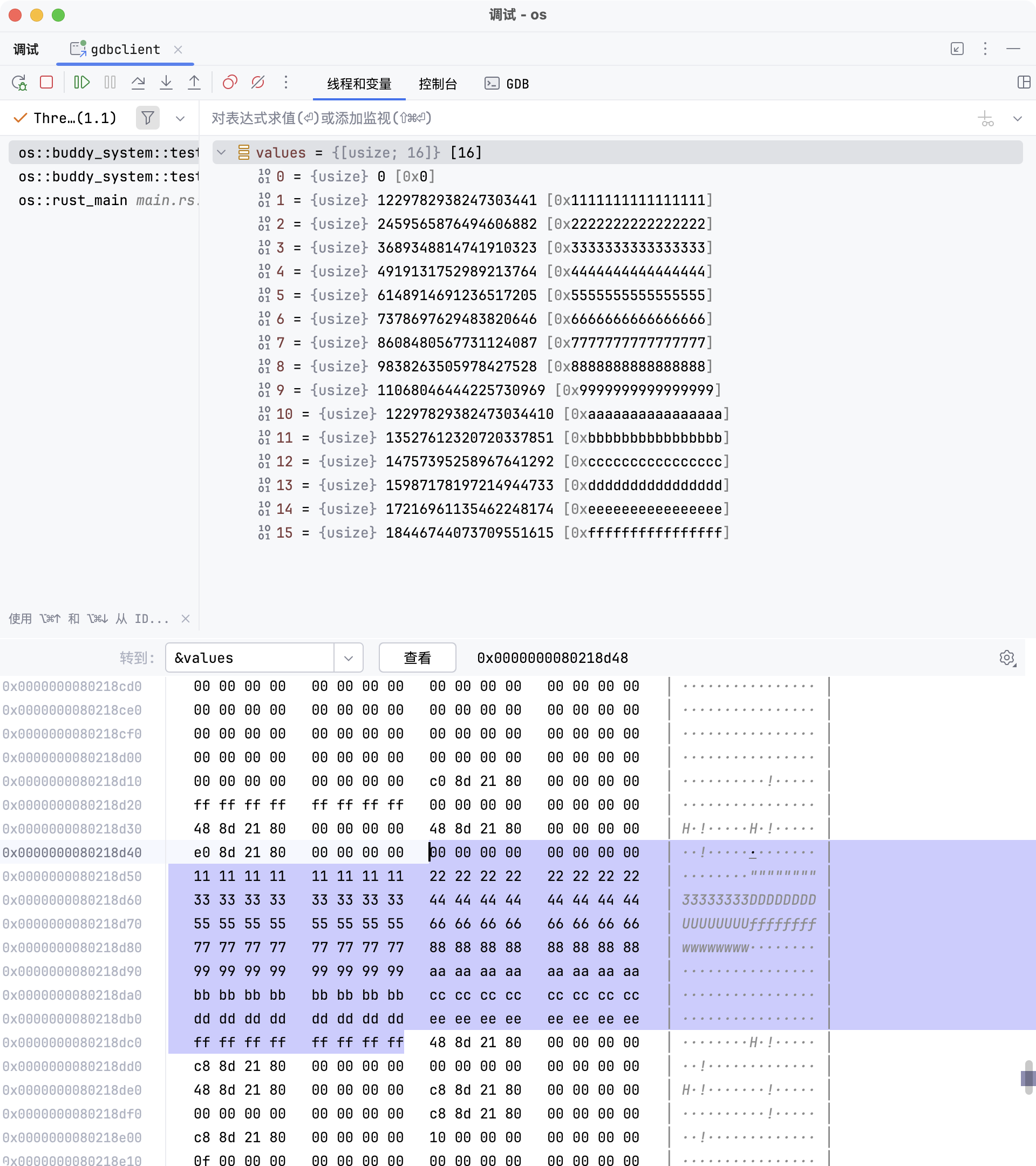
此时可以查看由 16 个元素组成的数组 values 的地址和值。为了便于调试和定位,每个元素的值都被赋予了有规律的数字。
这些数值本身并不重要,关键在于它们的内存地址。测试用例中,这些地址位于栈上;而在实际内存分配时,这些地址会对应到分配区域的内部。
values 数组的起始地址为 0x80218d48,下图显示了各个元素的值(即每个元素的初始内容):
新建链表
此时程序已执行完链表和节点的初始化,但尚未执行任何 push 操作。断点位于【5. 依次
push】之前。
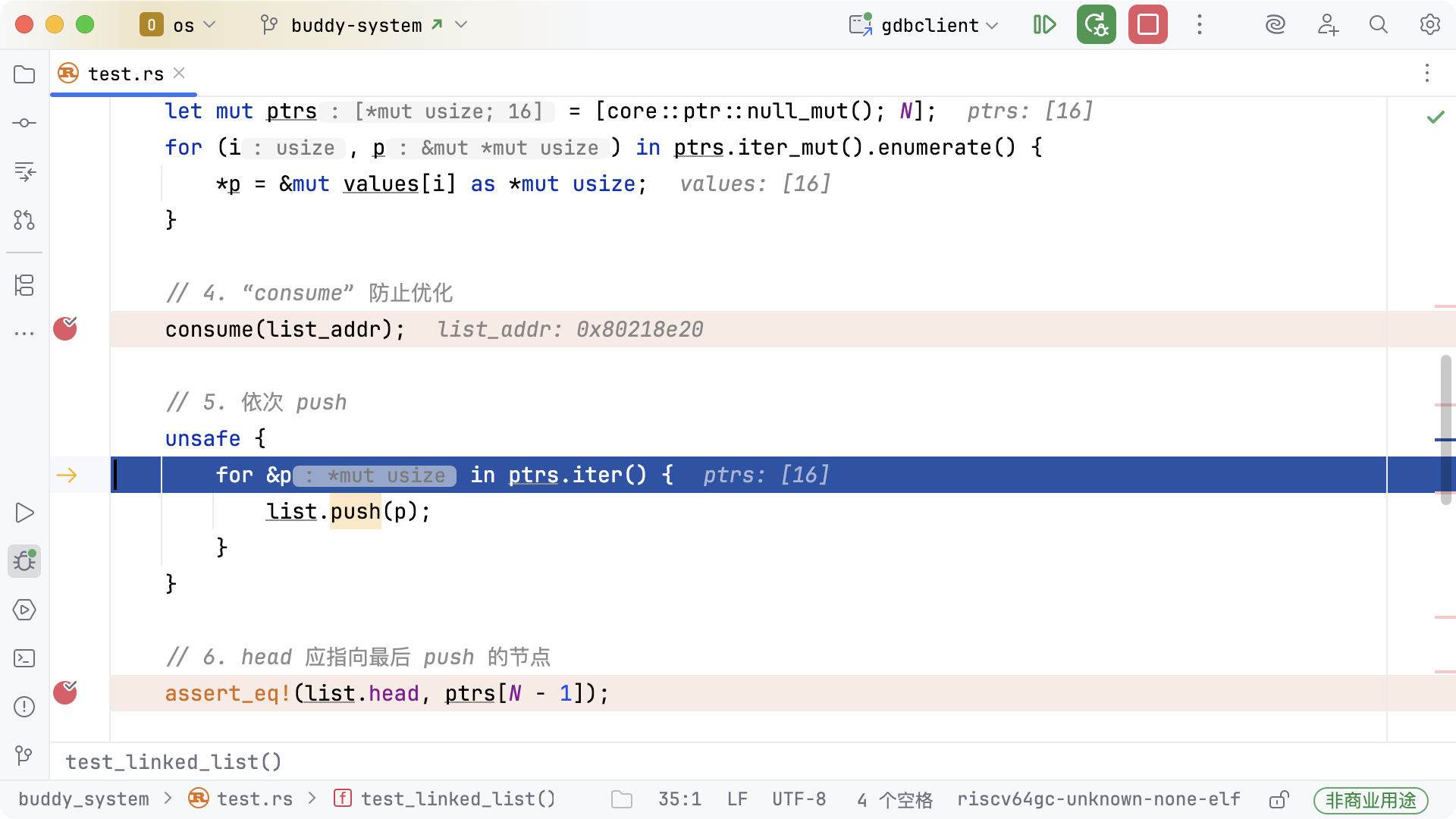
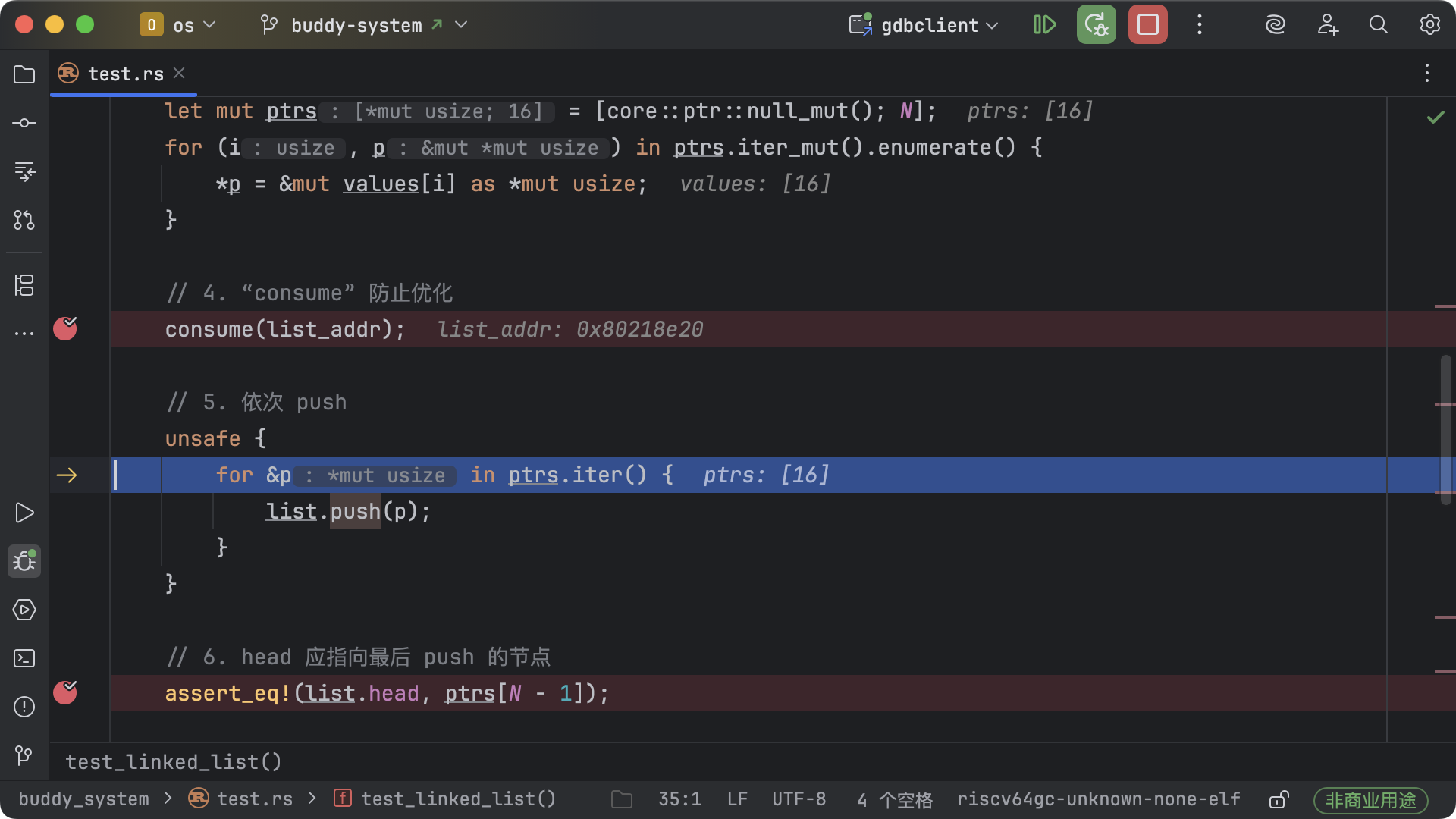
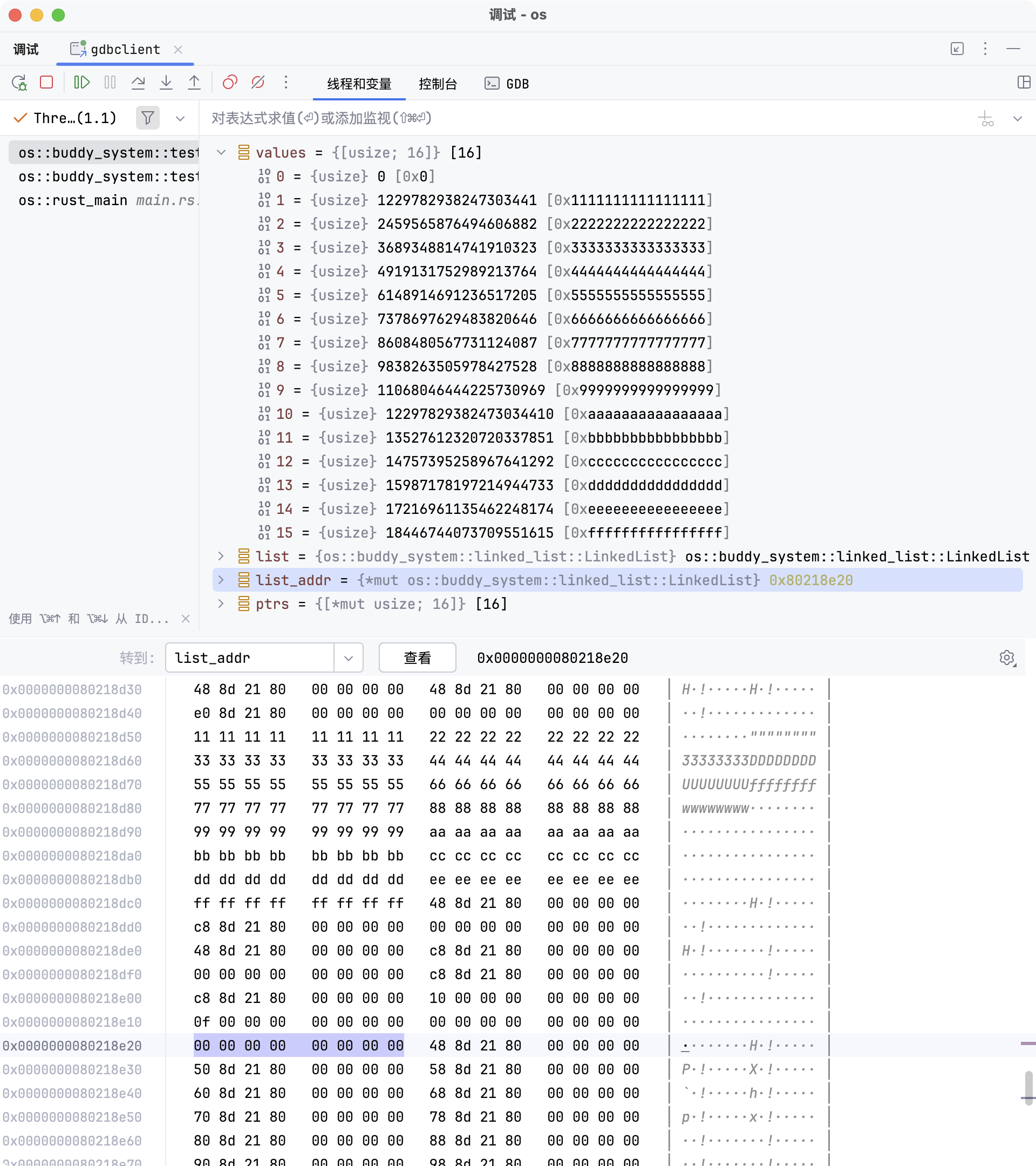
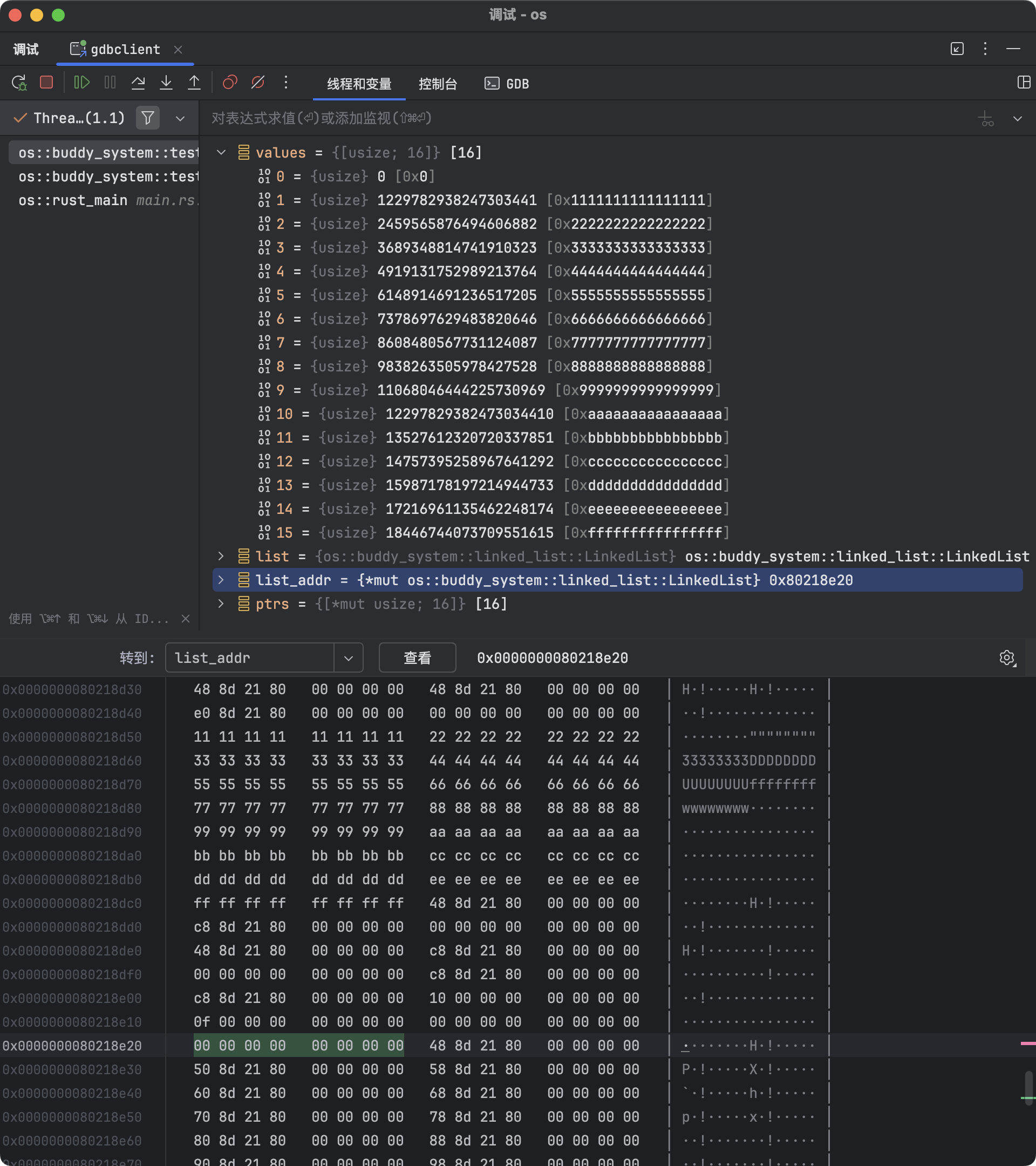
可以看到链表 list 位于栈上,其地址为 0x80218e20。此时
head 字段的值为 0x0,表示链表为空,没有任何节点被插入。
>>> p &list
$1 = (*mut os::buddy_system::linked_list::LinkedList) 0x80218e20
>>> p &list.head
$2 = (*mut *mut usize) 0x80218e20
>>> p list
$3 = os::buddy_system::linked_list::LinkedList {
head: 0x0
}
>>> p list.head
$4 = (*mut usize) 0x0由于 LinkedList 结构体仅包含 head 一个字段,因此
&list 与 &list.head 的地址相同,二者都为 0x80218e20。
插入节点
跳转到【6. head 应指向最后 push 的节点】的断点,此时所有节点已依次插入链表,head
字段指向最后插入的节点。
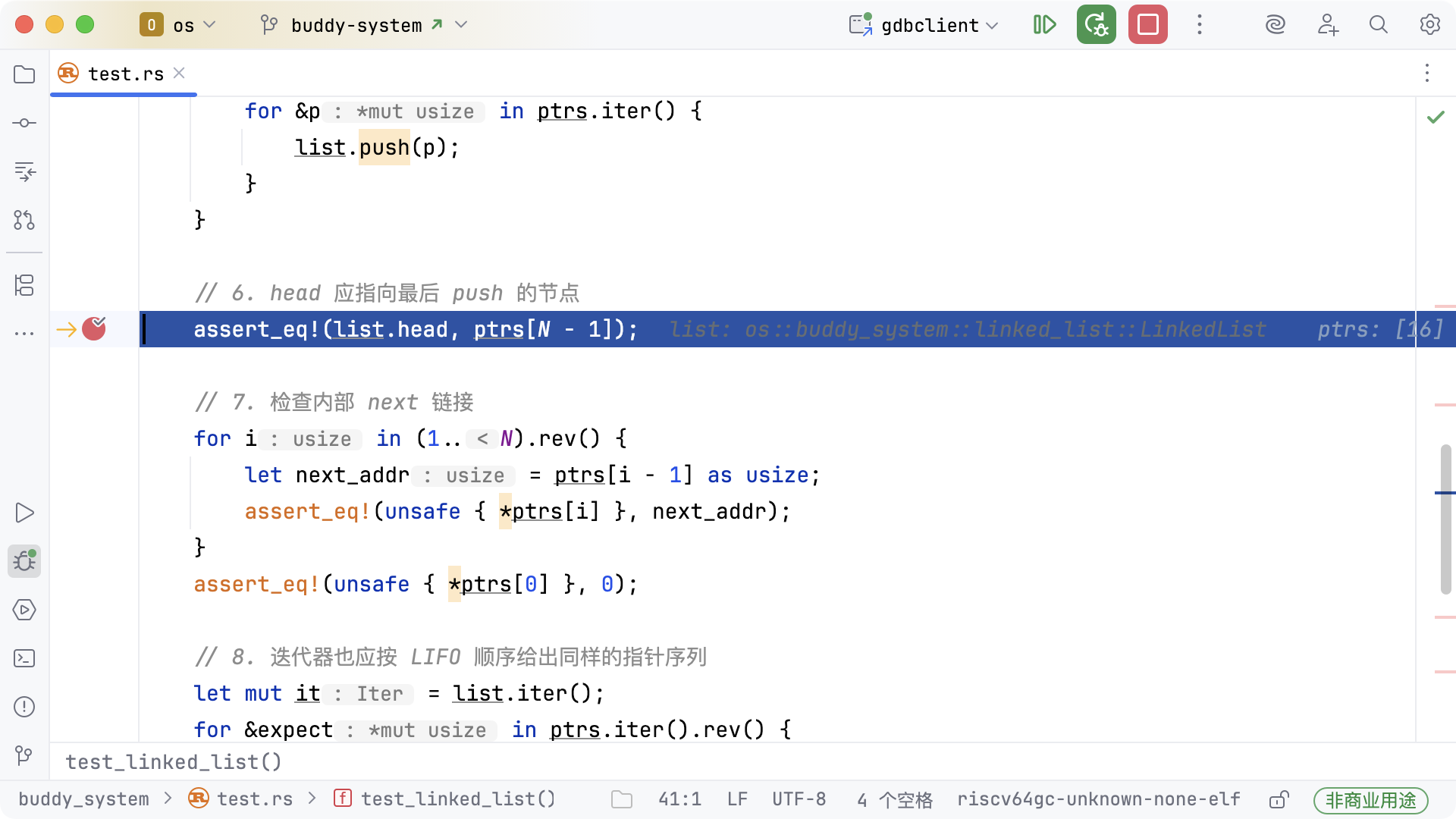
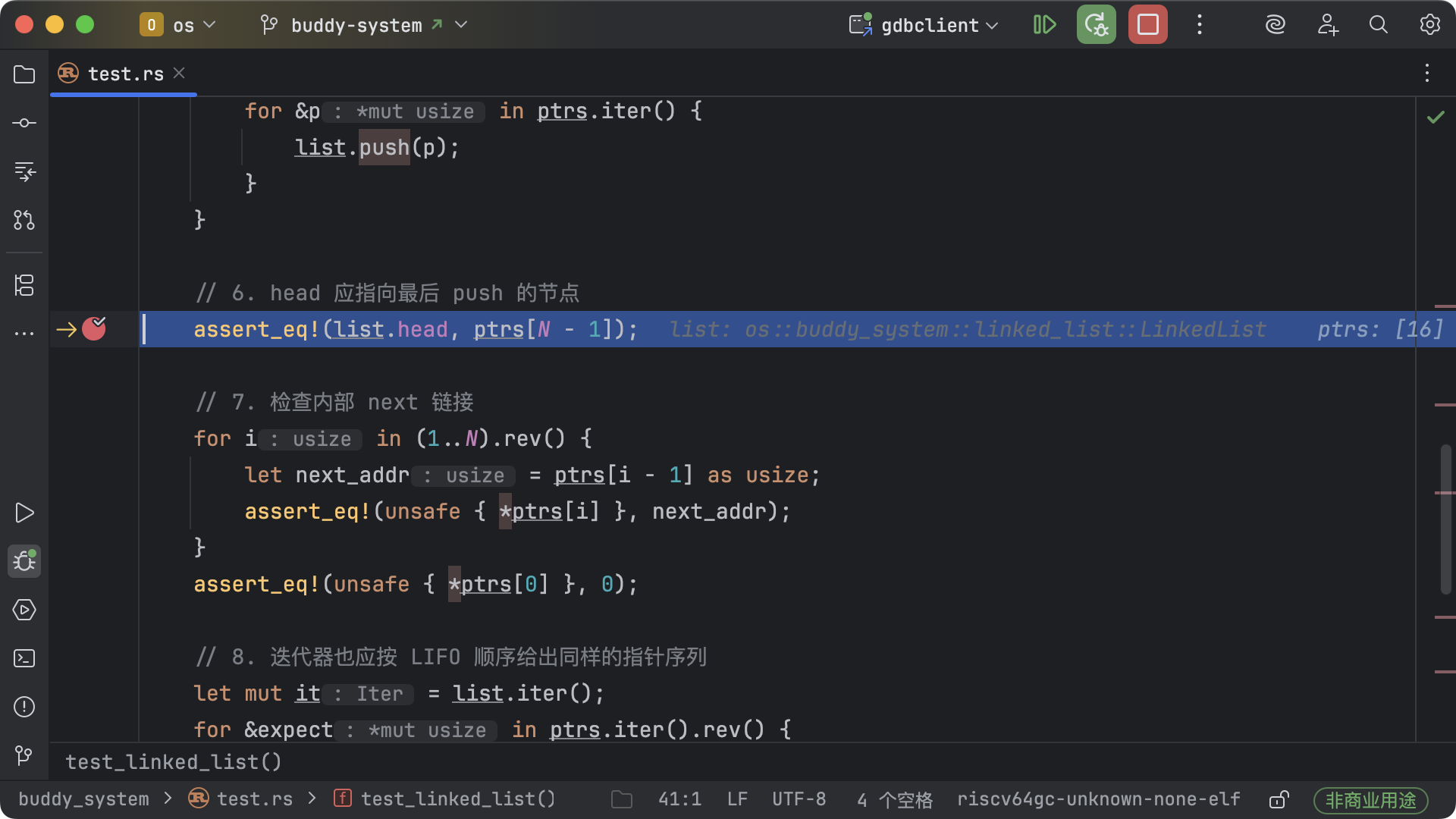
此时可以通过「内存视图」观察链表结构的变化:
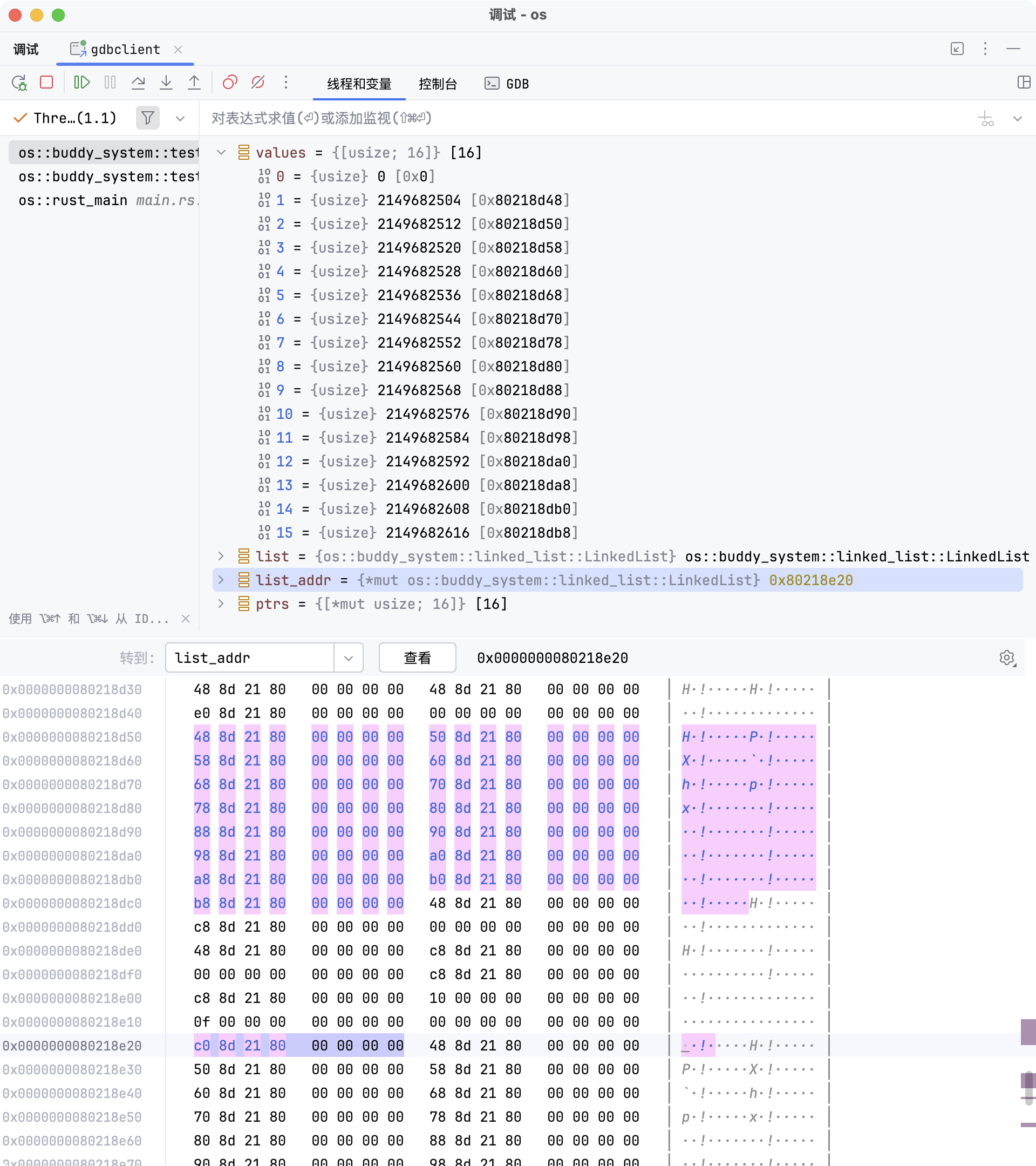
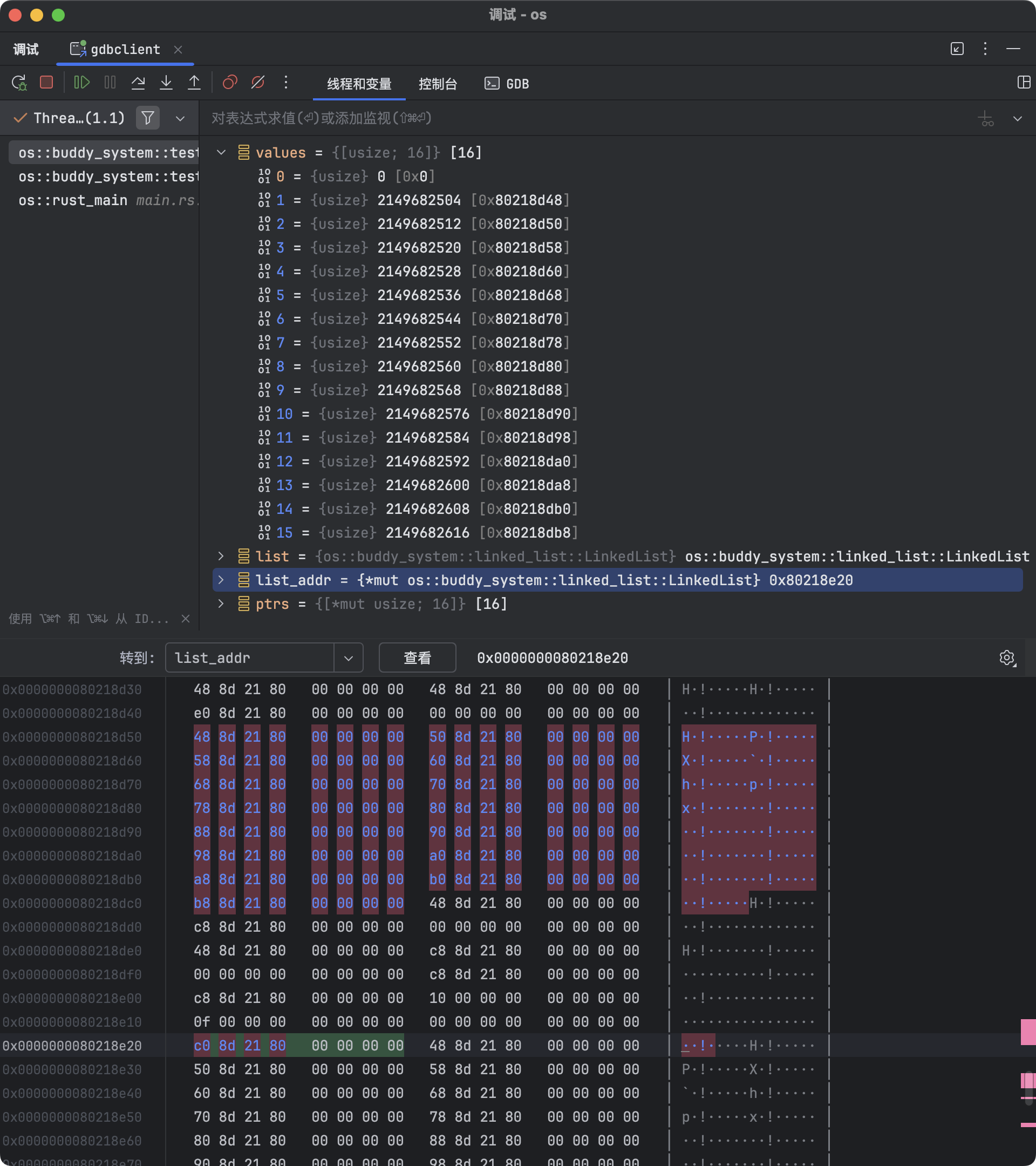
检视内存
此时可以使用 GDB 检查链表和节点的内存布局。例如:
>>> x /gx 0x80218e20
0x80218e20: 0x0000000080218dc0这里 0x80218e20 是链表 list 结构体的地址,存储的值 0x80218dc0 是
head 字段存储的指针,指向链表的首节点(最近插入的节点)的地址。
继续查看数组中各个元素的内容:
>>> x /16gx 0x80218d48
0x80218d48: 0x0000000000000000 0x0000000080218d48
0x80218d58: 0x0000000080218d50 0x0000000080218d58
0x80218d68: 0x0000000080218d60 0x0000000080218d68
0x80218d78: 0x0000000080218d70 0x0000000080218d78
0x80218d88: 0x0000000080218d80 0x0000000080218d88
0x80218d98: 0x0000000080218d90 0x0000000080218d98
0x80218da8: 0x0000000080218da0 0x0000000080218da8
0x80218db8: 0x0000000080218db0 0x0000000080218db8输出格式解读:左侧显示内存地址,右侧分为两列数据——第一列显示该地址存储的值,第二列显示该地址偏移 8 字节后存储的值。对于链表节点而言,这些值通常是指向下一个节点的地址,或者是表示链表末尾的 0x0。通过同时观察两个相邻内存位置的内容,可以更好地理解链表的指针连接关系。
链表 list 所在的地址为 0x80218e20,该地址存储的值是 values 数组最后一个元素的地址
0x80218dc0,也就是最近插入链表的节点地址。
这个最近插入的节点成为链表的首节点,其存储的值(next
指针)为下一个节点的地址 0x80218db8。
依次类推,每个节点的地址依次为
0x80218dc0、0x80218db8、...、0x80218d48,每个节点的值为下一个节点的地址。最早插入的节点(地址为
0x80218d48)的值为 0x0,表示它是链表的最后一个节点。
下图中,每一个矩形表示一个链表节点。左侧的红色背景表示该节点的内存地址,右侧的绿色背景表示该地址处存储的值(即下一个节点的地址或
0x0)。
需要注意的是,除了第一个数组元素的值刚好与空指针一致(0x0),其余元素的值都被后续节点的地址覆盖。


准备删除
跳转到【9. pop 也应以同样顺序逐个拿出】之前的断点。
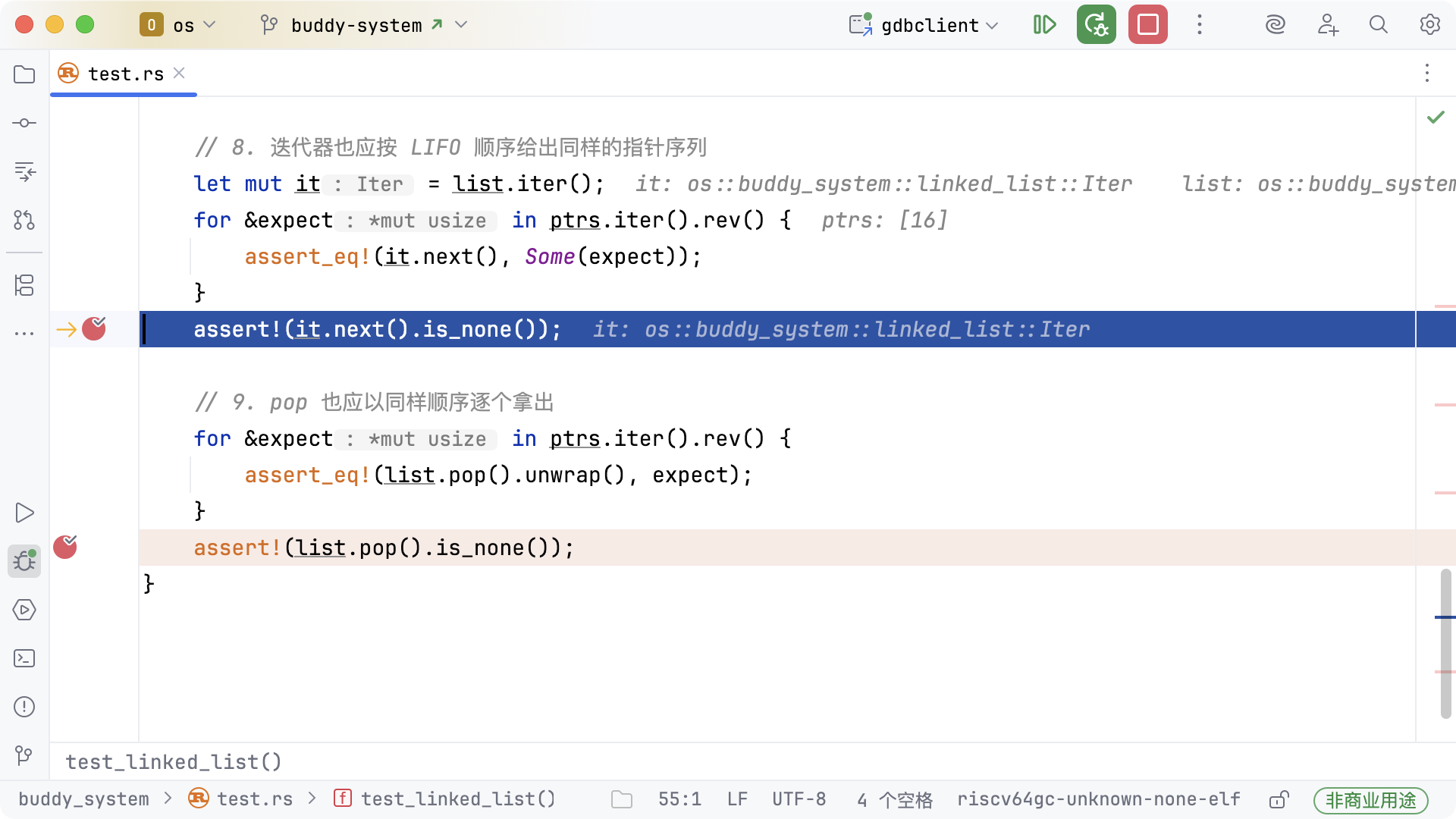
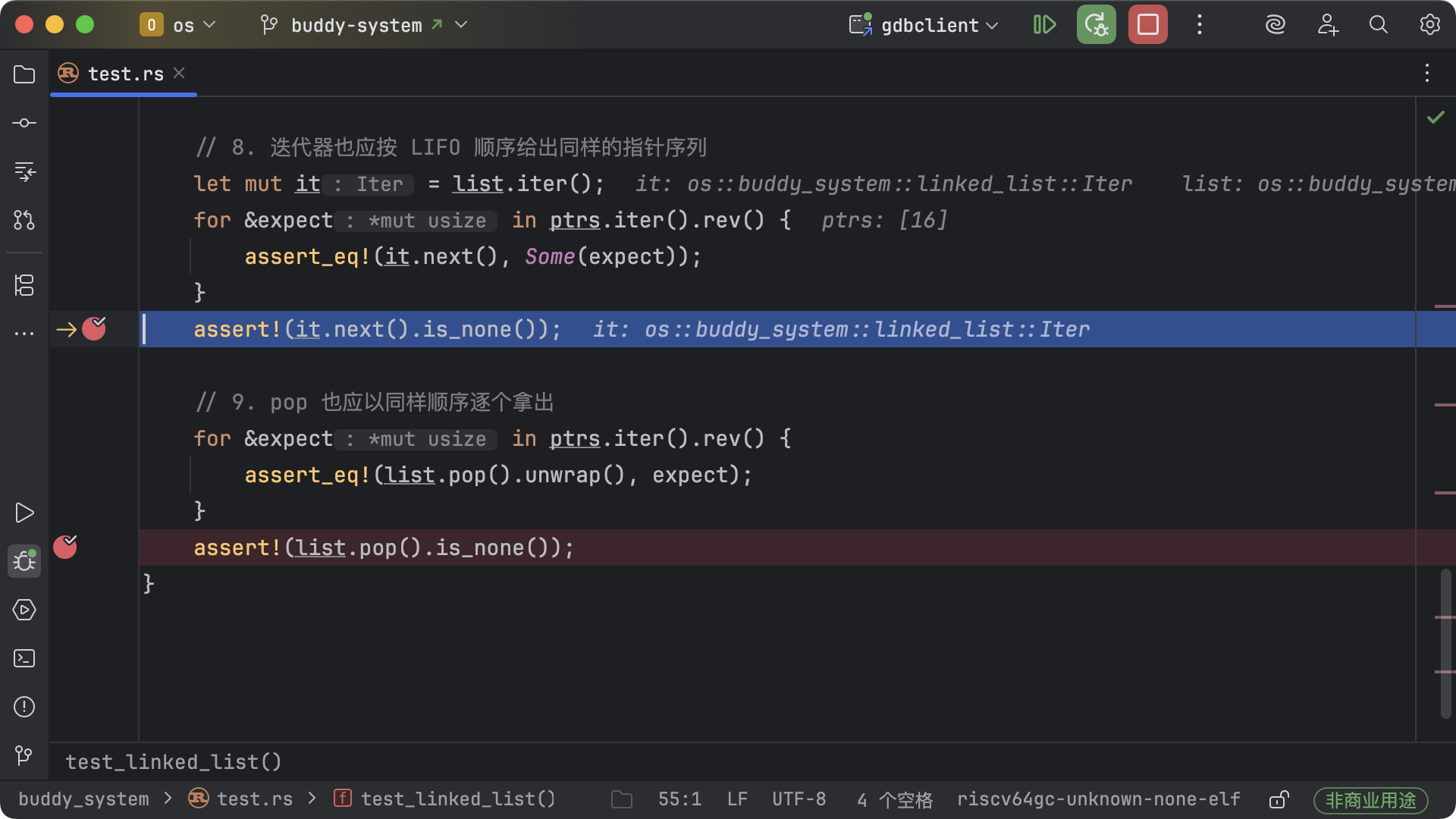
此时链表 list 所在的地址 0x80218e20 的值即将发生变化。
删除节点
跳转到【9. pop 也应以同样顺序逐个拿出】之后的断点。
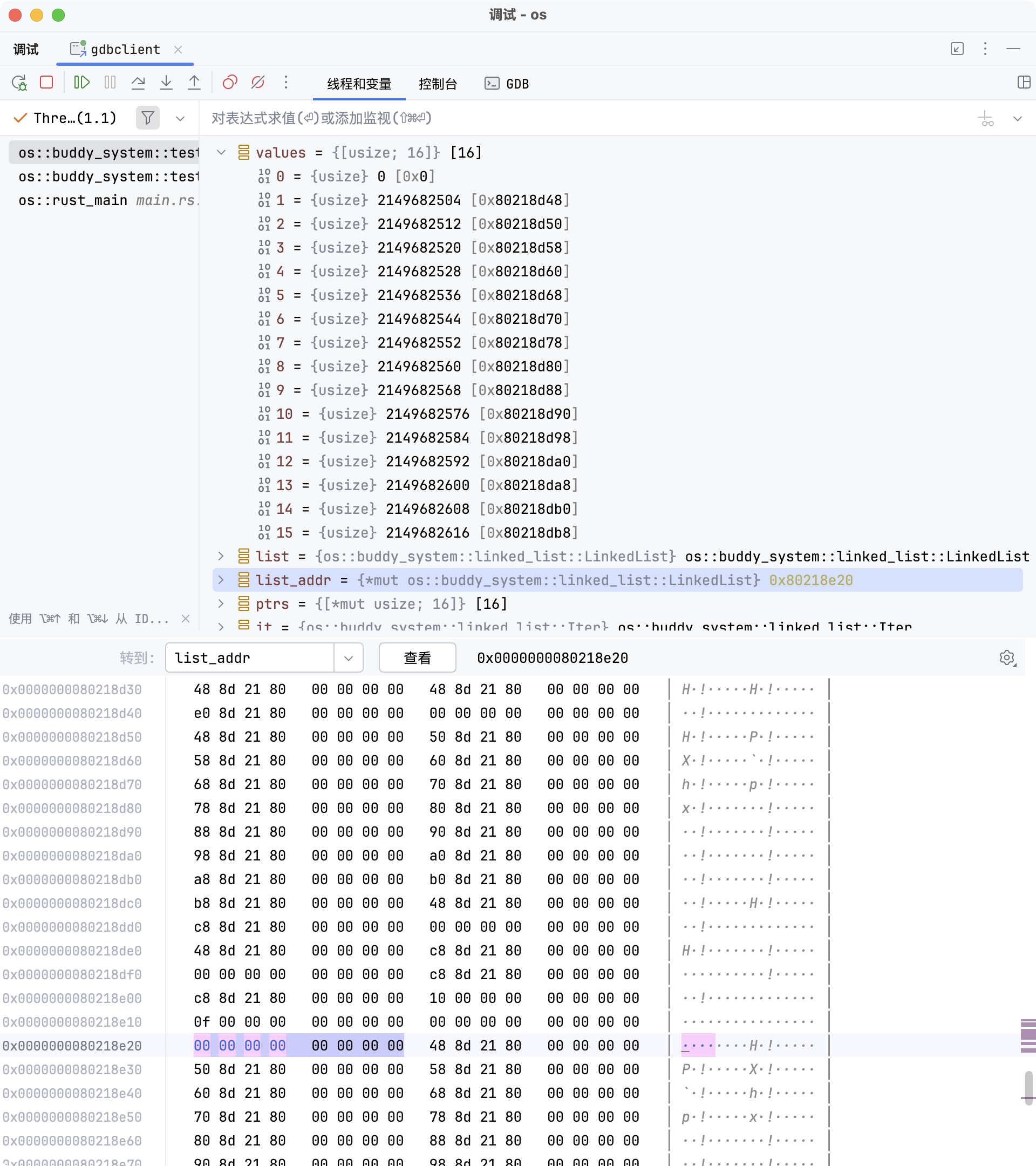
此时链表 list 所在的地址 0x80218e20 的值被赋值为
0x0,表示 head 字段被设为 null,即链表已为空。
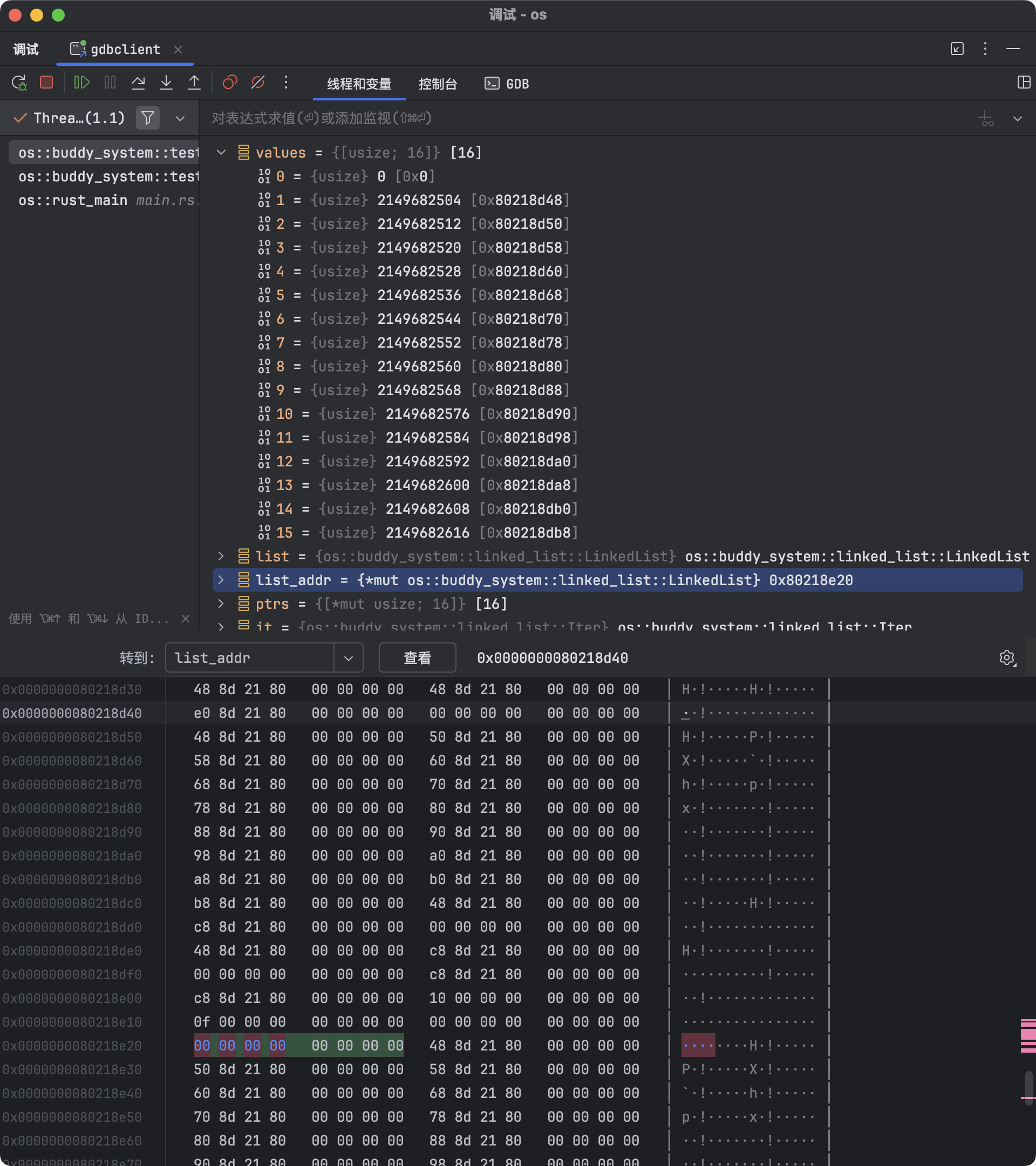
如果使用「步过」按钮逐行执行,可以看到 pop 与 push 不同,移除元素时只有链表
list 所在地址的值发生了改变。
迭代器
侵入式链表提供两种迭代器:
- 只读迭代器
Iter(通过iter()获取),按顺序访问节点指针,不可修改或删除; - 可变迭代器
IterMut(通过iter_mut()获取),遍历时可访问并通过ListNode::pop删除任意节点。
两种迭代器都直接操作内部指针,避免了额外的内存分配开销,并支持不同的访问模式。
伙伴系统堆
堆的相关代码见:
为便于调试,本仓库在原版实现基础上做了少量调整,但核心原理保持一致。
初始化
堆的初始化函数定义在 ctor.rs 中:
调用 Heap::<ORDER>::new() 时,会创建一个长度为 ORDER 的空链表数组 free_list,并将 user、allocated、total 均置为
0。通过调试可见,所有阶次的链表此时都为空,用于管理不同大小的空闲内存块:
以下以 ORDER = 32 为例,列出了每个阶次所管理的内存块大小:
| Order (Index) | Bytes per Node | Expression |
|---|---|---|
| 0 | 1 B | 1 << 0 |
| 1 | 2 B | 1 << 1 |
| 2 | 4 B | 1 << 2 |
| 3 | 8 B | 1 << 3 |
| 4 | 16 B | 1 << 4 |
| 5 | 32 B | 1 << 5 |
| 6 | 64 B | 1 << 6 |
| 7 | 128 B | 1 << 7 |
| 8 | 256 B | 1 << 8 |
| 9 | 512 B | 1 << 9 |
| 10 | 1 KiB | 1 << 10 |
| 11 | 2 KiB | 1 << 11 |
| 12 | 4 KiB | 1 << 12 |
| 13 | 8 KiB | 1 << 13 |
| 14 | 16 KiB | 1 << 14 |
| 15 | 32 KiB | 1 << 15 |
| 16 | 64 KiB | 1 << 16 |
| 17 | 128 KiB | 1 << 17 |
| 18 | 256 KiB | 1 << 18 |
| 19 | 512 KiB | 1 << 19 |
| 20 | 1 MiB | 1 << 20 |
| 21 | 2 MiB | 1 << 21 |
| 22 | 4 MiB | 1 << 22 |
| 23 | 8 MiB | 1 << 23 |
| 24 | 16 MiB | 1 << 24 |
| 25 | 32 MiB | 1 << 25 |
| 26 | 64 MiB | 1 << 26 |
| 27 | 128 MiB | 1 << 27 |
| 28 | 256 MiB | 1 << 28 |
| 29 | 512 MiB | 1 << 29 |
| 30 | 1 GiB | 1 << 30 |
| 31 | 2 GiB | 1 << 31 |
添加内存区间
相关代码见:
向堆中添加 [start, end) 区间时,先对起始和结束地址做指针对齐与校验。然后从对齐后的起点出发,循环执行以下步骤,直到空间耗尽:
- 计算当前地址和剩余长度能放入的最大阶次块(同时满足块对齐和剩余空间限制)。
- 将该块插入对应阶次的空闲链表。
- 将起始地址后移块大小,继续处理剩余区间。
下面以区间 [0x100000001, 0x2ffffffff) 为例,演示添加内存后的 Heap.free_list 状态(各阶链表按索引从 0 到 31 列出):
Heap {
user: 0x0, allocated: 0x0, total: 0x1fffffff0,
free_list[ 0]: [],
free_list[ 1]: [],
free_list[ 2]: [],
free_list[ 3]: [0x2fffffff0, 0x100000008],
free_list[ 4]: [0x2ffffffe0, 0x100000010],
free_list[ 5]: [0x2ffffffc0, 0x100000020],
free_list[ 6]: [0x2ffffff80, 0x100000040],
free_list[ 7]: [0x2ffffff00, 0x100000080],
free_list[ 8]: [0x2fffffe00, 0x100000100],
free_list[ 9]: [0x2fffffc00, 0x100000200],
free_list[10]: [0x2fffff800, 0x100000400],
free_list[11]: [0x2fffff000, 0x100000800],
free_list[12]: [0x2ffffe000, 0x100001000],
free_list[13]: [0x2ffffc000, 0x100002000],
free_list[14]: [0x2ffff8000, 0x100004000],
free_list[15]: [0x2ffff0000, 0x100008000],
free_list[16]: [0x2fffe0000, 0x100010000],
free_list[17]: [0x2fffc0000, 0x100020000],
free_list[18]: [0x2fff80000, 0x100040000],
free_list[19]: [0x2fff00000, 0x100080000],
free_list[20]: [0x2ffe00000, 0x100100000],
free_list[21]: [0x2ffc00000, 0x100200000],
free_list[22]: [0x2ff800000, 0x100400000],
free_list[23]: [0x2ff000000, 0x100800000],
free_list[24]: [0x2fe000000, 0x101000000],
free_list[25]: [0x2fc000000, 0x102000000],
free_list[26]: [0x2f8000000, 0x104000000],
free_list[27]: [0x2f0000000, 0x108000000],
free_list[28]: [0x2e0000000, 0x110000000],
free_list[29]: [0x2c0000000, 0x120000000],
free_list[30]: [0x280000000, 0x140000000],
free_list[31]: [0x200000000, 0x180000000]
}
可以看到,由于地址必须按 usize(64 位系统下为 8 字节)对齐,最低三个阶次对应的块(1 B、2 B、4 B)无法存放任何有效区间,因此
free_list[0]~free_list[2] 始终为空。整体累积的可用空间(total 字段)也比原始区间长度略小。
下图展示了各阶空闲区块在内存地址空间中的分布情况:


分配内存
相关代码见:
分配过程:
- 规范化
Layout,计算满足对齐和大小需求的最小阶次。 - 在该阶的空闲链表中查找可用块:
- 若存在,直接弹出并返回;
- 否则从更高阶借用块,依次拆分成两半,直到得到目标阶块,然后返回。
- 若遍历至最高阶仍无可用块,返回
OutOfMemory。
分配成功后,会更新 user(请求字节数)和 allocated(实际分配大小)等统计信息。
释放内存
相关代码见:
释放过程:
- 规范化
Layout,计算满足对齐和大小需求的最小阶次。 - 将释放块直接插入对应阶次的空闲链表。
- 从该阶开始逐级向上合并伙伴块:
- 根据当前阶次计算块大小与伙伴地址(两个块的地址按位异或等于块大小);
- 在同阶的空闲链表中查找此伙伴地址:
- 若找到,则将当前块和伙伴块同时从空闲链表中移除,并合并成更大阶次的块,新块的起始地址取两者中较小者,然后继续在更高阶查找;
- 若未找到,则结束合并。
- 更新统计信息:减去用户请求的字节数和对应的实际分配大小。
通过这种方式,释放的内存可以重新加入空闲链表,同时伙伴合并机制有助于减少内存碎片,提高连续可用空间的利用率。
到这里,我们介绍了伙伴系统的核心思想:用二次幂拆分与合并空闲块来应对不同大小的内存请求,并通过侵入式链表管理各阶空闲块。读者可以结合示例代码和调试流程来进一步理解算法的具体实现。


图示:二叉树结构示意图,说明伙伴系统的层次结构原理。每个节点代表一个内存块,可以分裂成两个子节点(较小的伙伴块),或与其伙伴节点合并成父节点(较大的内存块)。